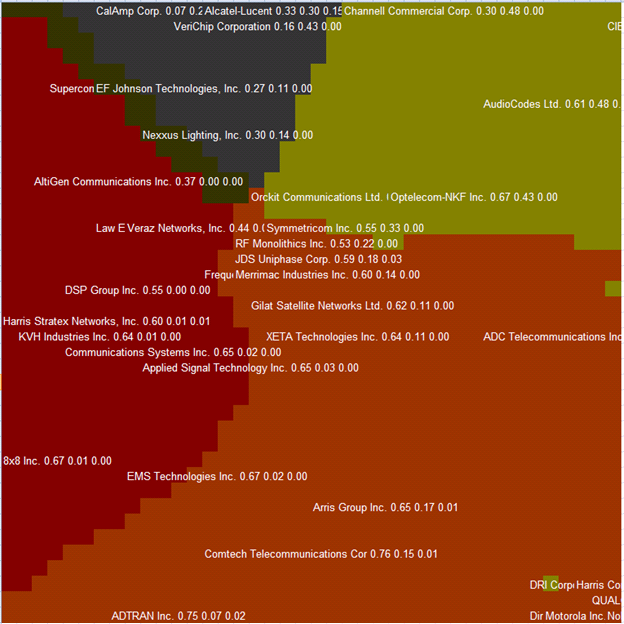
This program is a demo of graphical capabilities that Excel has. A
famous game of rock-paper-scissors forms the basis of
our simulated world. Each species consumes one neighbor and is in turn consumed
by another. A new entity of one’s own type is spawned, when food is consumed.
There is a need for
maintaining a dynamic balance – if one was to eat all of its food, only two
species would be present, and the focal species itself would be driven out as
it’s the weaker of the two.
There are a few
specific procedures created for this program: touching(object 1, object 2)
checks whether the two objects touch (this sub program can also be used to
check whether one block of cells is within another block of cells). Pause (s)
pauses the program for a period of time, also updating the graphical display. Arrays
are used for storing graphical objects.
Another example from Netlogo models shows the
dynamics of bird flocks. Bird flocks is the one program here that has been created by my TTU students, not me. These
students come from the same high school I once attended –
Tallinna Reaalkool.